How to Use Machine Learning for Building Powerful Recommendation Engines
In today's digital landscape, where consumers are overwhelmed with choices, the ability to deliver personalized experiences is no longer a luxury but a fundamental necessity. This is precisely where the power of machine learning for building recommendation engines comes into play. These sophisticated systems, often the backbone of industry giants like Netflix, Amazon, and Spotify, are designed to predict what a user might be interested in, thereby enhancing engagement, driving sales, and significantly improving the overall user experience. If you're looking to unlock unparalleled personalization and boost your business's bottom line, understanding how to leverage cutting-edge ML techniques for intelligent suggestions is absolutely critical.
Understanding Recommendation Engines and Their Indispensable Role
At its core, a recommendation engine is an information filtering system that predicts the "rating" or "preference" a user would give to an item. Imagine a virtual sales assistant, tirelessly working 24/7, learning from every interaction to offer the most relevant products, movies, or songs. This capability transforms passive browsing into an active, guided discovery, fostering customer loyalty and increasing lifetime value. Without intelligent recommendations, users often face decision fatigue, leading to higher bounce rates and missed opportunities for conversion.
Before the advent of advanced machine learning, recommendation systems were often rudimentary, relying on simple metrics like "most popular items" or "recently viewed." While these offered some utility, they lacked the nuanced understanding of individual preferences that modern AI-powered recommendation systems provide. The shift to machine learning has allowed for dynamic, adaptable, and highly personalized suggestions that evolve with user behavior and market trends.
Why Businesses Absolutely Need Recommendation Engines
- Enhanced User Engagement: By presenting highly relevant content, recommendation engines keep users on your platform longer, exploring more items.
- Increased Sales and Conversions: Personalized product suggestions directly lead to higher purchase rates and larger average order values.
- Improved Customer Retention: A tailored experience makes users feel understood and valued, fostering loyalty and repeat business.
- Discovery of New Content/Products: Users are introduced to items they might not have found otherwise, broadening their horizons and deepening their interaction.
- Valuable Data Insights: The process of building and maintaining these engines generates rich data about user preferences and item relationships, informing broader business strategies.
The Machine Learning Foundation of Recommendation Systems
Building a robust recommendation engine involves several critical machine learning paradigms, each with its strengths and ideal use cases. The choice of approach often depends on the type of data available, the business goals, and the desired complexity of the system.
Data Collection and Preprocessing: The Unsung Hero
No machine learning model, however sophisticated, can perform well without high-quality data. For recommendation engines, this means gathering diverse information and preparing it meticulously. Data can be broadly categorized:
- Explicit Feedback: Direct user input, such as ratings (e.g., 1-5 stars), likes/dislikes, or reviews. This is the most straightforward signal of preference.
- Implicit Feedback: Indirect observations of user behavior, such as viewing history, clicks, purchases, search queries, time spent on a page, or even mouse movements. While less direct, implicit feedback is often more abundant and easier to collect at scale.
- User Data: Demographics (age, gender, location), past purchase history, browsing patterns, stated preferences, and social network connections.
- Item Data: Attributes of the items being recommended, such as genre, category, description, actors, price, brand, or technical specifications.
Once collected, this raw data requires extensive data preprocessing. This involves cleaning (handling missing values, outliers), normalization, and importantly, feature engineering. Feature engineering is the art of transforming raw data into features that better represent the underlying problem to the machine learning models. For instance, converting timestamps into "day of the week" or "hour of the day" could reveal temporal patterns in user behavior. Creating a "user-item interaction matrix" is a common step, even if it's sparse.
Key Machine Learning Paradigms for Recommendations
The core of any recommendation engine lies in its algorithms. Here are the most prominent ML approaches:
Collaborative Filtering
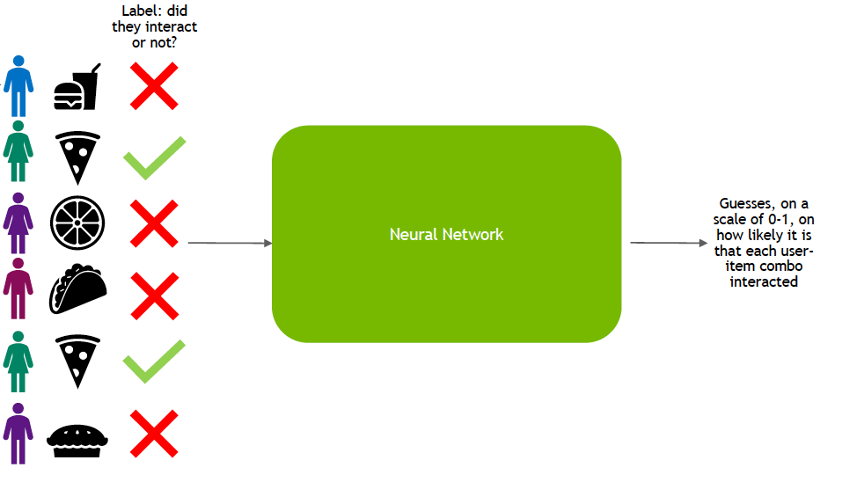
This is perhaps the most widely recognized and powerful approach. Collaborative filtering operates on the principle that people who agreed in the past on certain items will agree again in the future. It doesn't require any information about the items themselves, only user-item interactions.
- User-Based Collaborative Filtering: Identifies users with similar tastes (nearest neighbors) and recommends items that those "similar users" liked but the current user hasn't seen yet.
- Item-Based Collaborative Filtering: Identifies items that are similar to items the user has already liked. This is often more scalable than user-based, especially with a large number of users.
- Matrix Factorization (e.g., SVD, ALS): A more advanced technique that decomposes the sparse user-item interaction matrix into a product of two lower-dimensional matrices representing latent factors for users and items. These latent factors capture hidden features or characteristics that explain user preferences and item attributes. It's highly effective for handling data sparsity and scales well.
Content-Based Filtering
Unlike collaborative filtering, content-based filtering recommends items that are similar to items the user has liked in the past. It relies heavily on the attributes or characteristics of the items themselves and the user's profile. For example, if a user likes action movies, the system will recommend other action movies based on their genre, actors, directors, etc. Techniques like TF-IDF (Term Frequency-Inverse Document Frequency) and cosine similarity are often used to measure item similarity.
Hybrid Recommendation Systems
Most state-of-the-art recommendation engines today are hybrid recommendation systems. These combine the strengths of collaborative filtering and content-based filtering to mitigate their individual weaknesses (e.g., the cold start problem for collaborative filtering, or limited diversity for content-based). Common hybrid approaches include:
- Weighted Hybrid: Combining scores from different models.
- Switching Hybrid: Switching between models based on context.
- Mixed Hybrid: Presenting recommendations from different models side-by-side.
- Feature Combination Hybrid: Feeding features from one model into another.
Deep Learning for Recommendations
The rise of deep learning has revolutionized recommendation systems, allowing for the capture of highly complex patterns and relationships that traditional methods might miss. Neural networks can learn intricate representations (embeddings) of users and items from raw data, including images, text, and sequential behavior. Approaches include:
- Autoencoders: Neural networks trained to reconstruct their input, learning compressed representations (embeddings) in the process, which can then be used for recommendations.
- Recurrent Neural Networks (RNNs) and Transformers: Excellent for sequential data, such as a user's viewing history, to predict the next item they might be interested in. This is particularly useful for sequential recommendation tasks.
- Graph Neural Networks (GNNs): Ideal for modeling complex relationships within a graph structure (e.g., users connected to items, items connected to other items). They can capture higher-order dependencies.
- Deep Factorization Models: Combining the strengths of matrix factorization with deep neural networks to learn non-linear relationships.
Building a Recommendation Engine: A Step-by-Step Guide
Developing a functional and effective recommendation engine is an iterative process that requires careful planning, execution, and continuous optimization.
Step 1: Defining the Problem and Data Acquisition
Before writing any code, clearly define what you want your recommendation engine to achieve. Are you aiming to increase product sales, boost content consumption, or improve user retention? The goal will dictate the data you need and the algorithms you choose. Identify all potential data sources within your organization – user profiles, purchase history, clickstreams, search logs, item metadata, and more. Consider if you need to integrate external data sources.
Step 2: Data Preprocessing and Feature Engineering
This foundational step is crucial. Collect your raw data and begin the cleaning process: handling missing values (imputation or removal), addressing duplicates, and correcting inconsistencies. Then, focus on feature engineering. This involves creating new features from existing ones that could be more informative for your model. For instance, deriving "time since last purchase" or "number of unique categories viewed" can be powerful. For textual data, techniques like TF-IDF or word embeddings are essential. For categorical data, one-hot encoding is common. Ensure your data is in a format suitable for the chosen ML algorithms, often a user-item interaction matrix, whether sparse or dense.
Step 3: Model Selection and Training
Based on your data characteristics and objectives, select the appropriate machine learning algorithm(s). Start simple (e.g., item-based collaborative filtering) and progressively explore more complex models like matrix factorization or deep learning architectures if needed. Train your chosen model(s) on your preprocessed data. This involves feeding the data to the algorithm so it can learn the underlying patterns and relationships. Hyperparameter tuning – adjusting parameters like learning rate, number of latent factors, or network architecture – is critical at this stage to optimize model performance.
Step 4: Model Evaluation and Optimization
Once trained, your model needs to be rigorously evaluated. This involves using a separate dataset (test set) that the model hasn't seen during training. Common performance metrics for recommendation systems include:
- RMSE (Root Mean Squared Error) / MAE (Mean Absolute Error): For rating prediction tasks, measuring the accuracy of predicted ratings.
- Precision@K / Recall@K: For ranking tasks, measuring how many of the top K recommendations are relevant.
- NDCG (Normalized Discounted Cumulative Gain): A more sophisticated metric that considers the position of relevant items in the ranked list.
- Coverage: The proportion of items that can be recommended.
- Diversity: The dissimilarity among recommended items.
- Serendipity: The degree to which recommendations are surprising yet relevant.
Beyond offline metrics, A/B testing is vital for online evaluation. Deploy different versions of your recommendation engine to subsets of users and measure real-world impact on key business metrics like conversion rates, click-through rates, and user engagement. This iterative process of evaluation and optimization is key to continuous improvement.
Step 5: Deployment and Monitoring
After successful evaluation, deploy your recommendation engine into your production environment. This often involves building APIs that allow your application to query the engine for recommendations in real-time or via batch processing. Consider scalability and latency requirements. Post-deployment, continuous monitoring is essential. Track model performance, detect data drift (changes in user behavior or item characteristics), and identify potential biases. Regular retraining of models with fresh data is crucial to maintain relevance and accuracy. For larger systems, consider architectures that support real-time recommendations and online learning.
Addressing Common Challenges in Recommendation Engines
While powerful, recommendation engines come with their own set of challenges that need strategic solutions.
- The Cold Start Problem: How do you recommend items to a brand-new user with no interaction history, or recommend a brand-new item that no one has interacted with yet?
Solutions: For new users, recommend popular items, ask for initial preferences, or use demographic data. For new items, use content-based filtering until enough interaction data is gathered. Hybrid systems are particularly effective here.
- Sparsity: Most user-item matrices are extremely sparse (users interact with only a tiny fraction of available items), making it difficult to find reliable patterns.
Solutions: Matrix factorization methods are designed to handle sparsity. Deep learning models can also learn robust embeddings from sparse data. Implicit feedback, which is more abundant, can also help.
- Scalability: Handling millions of users and items with real-time prediction requirements demands highly scalable infrastructure and efficient algorithms.
Solutions: Distributed computing frameworks (e.g., Apache Spark), approximate nearest neighbor search algorithms, and highly optimized deep learning models are essential. Pre-computing recommendations for batch processing can also reduce real-time load.
- Serendipity vs. Relevance: Striking the right balance between recommending highly relevant items (which users expect) and introducing them to novel, unexpected items they might love (serendipity). Too much relevance can lead to a "filter bubble."
Solutions: Introduce a degree of randomness, explore diverse recommendation sets, or incorporate novelty metrics into your evaluation. Content-based methods can help here by suggesting items outside a user's typical interaction pattern but within their inferred interests.
- Ethical Considerations and Bias: Recommendation engines can inadvertently perpetuate or amplify biases present in the training data, leading to unfair or discriminatory recommendations.
Solutions: Implement fairness metrics, audit data for biases, use debiasing techniques in algorithms, and ensure transparency in how recommendations are generated. Explore Explainable AI (XAI) techniques to understand model decisions.
Future Trends and Advanced Concepts
The field of recommendation systems is constantly evolving, driven by advancements in AI and the increasing demand for hyper-personalization. Key trends include:
- Reinforcement Learning (RL): Treating recommendation as a sequential decision-making problem, where the system learns to optimize long-term user engagement by observing the impact of its recommendations.
- Context-Aware Recommendations: Incorporating contextual information such as time of day, location, device, or even emotional state to provide even more relevant suggestions.
- Explainable AI (XAI): Developing models that not only provide recommendations but also explain why a particular item was suggested, building user trust and allowing for easier debugging of biases.
- Graph Neural Networks (GNNs): Gaining traction for their ability to model complex relationships between users, items, and other entities in a graph structure, leading to richer representations and more accurate recommendations.
- Federated Learning: Enabling collaborative model training across multiple devices or organizations without sharing raw user data, addressing privacy concerns.
Frequently Asked Questions
What is the cold start problem and how is it addressed in recommendation engines?
The cold start problem refers to the challenge of making recommendations for new users or new items when there is insufficient historical data. For a new user, the system lacks information about their preferences. For a new item, there are no interactions from existing users. This is a common hurdle when using collaborative filtering. It's addressed by employing strategies such as recommending popular items, asking new users for initial preferences, leveraging demographic data, or using content-based filtering for new items based on their attributes until enough user interaction data becomes available. Hybrid recommendation systems are particularly effective at mitigating this issue by combining different approaches.
What's the fundamental difference between collaborative filtering and content-based filtering?
The fundamental difference lies in how they determine similarity. Collaborative filtering relies on user-item interaction data to find similar users or similar items. It recommends items based on what similar users liked or what items are similar to those the user has already interacted with. It doesn't need to know anything about the items themselves. In contrast, content-based filtering recommends items that are similar in attributes or features to items a user has liked in the past. It primarily uses item metadata (e.g., genre, description, actors) and the user's profile to make recommendations. For example, if you watch many sci-fi movies, a content-based system will recommend other sci-fi movies based on their genre tags, while a collaborative filtering system might recommend movies liked by people who also watched the same sci-fi movies as you.
How do you measure the success of a machine learning recommendation engine?
Measuring success involves both offline and online metrics. Offline, you evaluate the model's predictive accuracy using metrics like RMSE (Root Mean Squared Error) or MAE (Mean Absolute Error) for rating prediction, and Precision@K, Recall@K, or NDCG (Normalized Discounted Cumulative Gain) for ranking quality. However, the true success is measured online through A/B testing, where different recommendation strategies are deployed to user segments, and their impact on key business metrics is observed. These business metrics include increased user engagement (e.g., click-through rates, time spent on site), higher conversion rates (e.g., purchases, subscriptions), improved customer retention, and overall user satisfaction. A successful engine drives tangible business value and a positive user experience.
Can I build a recommendation engine without deep programming knowledge?
While a deep understanding of programming and machine learning concepts is beneficial for building highly customized and complex recommendation engines from scratch, the landscape has evolved significantly. There are now numerous open-source libraries (e.g., Surprise, LightFM in Python) and cloud-based machine learning platforms (e.g., AWS Personalize, Google Cloud Recommendations AI) that abstract away much of the underlying complexity. These tools provide pre-built algorithms and managed services, allowing users with less deep programming knowledge to implement functional recommendation systems. However, understanding data preprocessing, model evaluation, and the core concepts of different recommendation algorithms remains crucial for effective implementation and optimization.
0 Komentar