How to Implement a Recommendation System Using Collaborative Filtering: A Comprehensive SEO Guide
In today's digital landscape, delivering highly personalized experiences is paramount for engaging users and driving business growth. A well-implemented recommendation system is no longer a luxury but a necessity for platforms ranging from e-commerce giants to streaming services. Among the various approaches, collaborative filtering stands out as a powerful and widely adopted technique. This comprehensive guide will walk you through the intricate process of how to implement a recommendation system using collaborative filtering, providing actionable insights and expert tips to ensure your system is robust, scalable, and delivers exceptional value.
Understanding the Core of Collaborative Filtering
Before diving into the implementation specifics, it’s crucial to grasp the fundamental principles of collaborative filtering. At its heart, collaborative filtering (CF) makes predictions about a user's interests by collecting preferences or taste information from many users. The core idea is that if users A and B share similar tastes on a set of items, then user A is likely to prefer items that user B liked but A has not yet encountered. This method primarily relies on past user behavior and interactions, rather than item attributes.
User-Based vs. Item-Based Collaborative Filtering
There are two primary paradigms within collaborative filtering, each with its own strengths and use cases:
- User-Based Collaborative Filtering (User-User CF): This approach identifies users who are similar to the target user based on their historical interactions (e.g., ratings, purchases, views). Once similar users are found, items that these "neighbors" liked but the target user hasn't seen are recommended.
- Pros: Can recommend novel items, good for niche communities.
- Cons: Suffers from scalability issues with a large number of users, susceptible to the "cold start" problem for new users.
- Item-Based Collaborative Filtering (Item-Item CF): This method, often more popular in large-scale systems, finds similarities between items based on how users have interacted with them. If item A and item B are frequently liked by the same users, they are considered similar. When a user interacts with item A, similar item B can be recommended.
- Pros: More stable as item similarity often changes less frequently than user preferences, better scalability for large user bases.
- Cons: Can struggle with recommending diverse items, may perpetuate popularity bias.
For most modern implementations, item-based collaborative filtering is often preferred due to its superior scalability and ability to handle larger datasets more efficiently. However, understanding both is vital for designing a flexible recommendation engine.
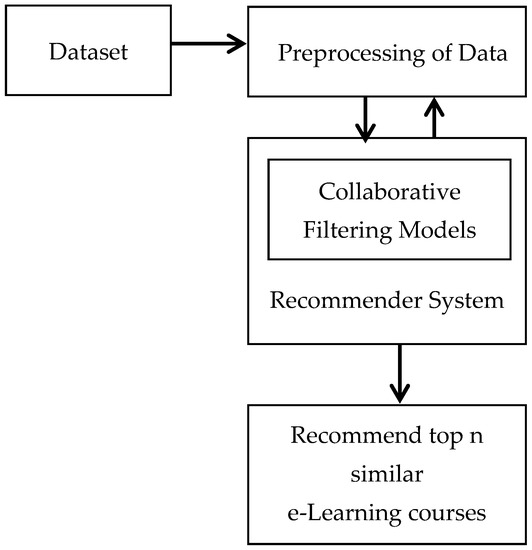
Phase 1: Data Acquisition and Preprocessing for Your Recommendation Engine
The quality of your recommendation system is directly tied to the quality of your input data. This phase is critical for any machine learning project.
Identifying Relevant Data Sources
To build a robust collaborative filtering system, you need data that captures user-item interactions. This can be:
- Explicit Feedback: Direct ratings (e.g., 1-5 stars), likes/dislikes, reviews. This data is clear but often sparse.
- Implicit Feedback: User actions that suggest preference, such as purchase history, view duration, clicks, searches, or time spent on a page. This data is abundant but requires careful interpretation. Most large-scale systems rely heavily on implicit feedback due to its sheer volume.
For an e-commerce platform, your data might consist of user IDs, product IDs, and purchase timestamps. For a movie streaming service, it would be user IDs, movie IDs, and watch duration or explicit ratings. The key is to form a user-item interaction matrix.
Data Preprocessing Steps
Raw data is rarely ready for direct use. Effective preprocessing is key:
- Data Collection & Storage: Ensure you have a reliable system for collecting and storing user interaction data. This could be a SQL database, NoSQL database, or data lake.
- Handling Missing Values: Collaborative filtering relies on known interactions. Missing values in your user-item matrix represent unknown preferences, not necessarily dislikes.
- Data Normalization: If using explicit ratings, normalizing them can help account for individual rating biases (e.g., some users always rate high).
- Sparsity Management: Real-world user-item matrices are inherently sparse, meaning most users have interacted with only a small fraction of available items. Techniques like creating a minimum interaction threshold (e.g., only include users who have interacted with at least X items) can help.
- User and Item ID Mapping: Convert raw user and item identifiers into numerical indices for efficient processing by algorithms.
Practical Tip: Start with a smaller, representative sample of your data to prototype your system before scaling up. This helps in quickly iterating and debugging your CF algorithms.
Phase 2: Choosing Similarity Metrics and Building the Model
Once your data is clean and structured, the next step is to quantify the similarity between users or items.
Selecting Appropriate Similarity Measures
The choice of similarity metrics significantly impacts the quality of recommendations. Common choices include:
- Cosine Similarity: Measures the cosine of the angle between two vectors. It's widely used, especially for sparse data, as it focuses on the orientation rather than the magnitude of the vectors. It's excellent for implicit feedback data.
- Pearson Correlation Coefficient: Measures the linear correlation between two sets of data. It's good for explicit rating data as it accounts for rating biases by centering the ratings around the mean.
- Euclidean Distance: Measures the straight-line distance between two points in Euclidean space. Less common for collaborative filtering due to its sensitivity to the magnitude of ratings and sparsity.
- Jaccard Similarity: Useful for binary data (e.g., presence/absence of an item in a user's liked list). Measures the size of the intersection divided by the size of the union of two sets.
For most item-based collaborative filtering systems, cosine similarity is a robust and popular choice, particularly when dealing with implicit feedback or large, sparse datasets.
Implementing the Collaborative Filtering Model
The core of the implementation involves computing similarities and generating recommendations. Python libraries like SciPy, Scikit-learn, and specialized libraries like Surprise make this process much more manageable.
Step-by-Step Model Construction (Item-Based Example):
- Create User-Item Matrix: Transform your preprocessed data into a matrix where rows are users, columns are items, and values represent interactions (e.g., ratings, binary 0/1 for purchased/viewed). Use sparse matrix formats (e.g., CSR matrix from SciPy) to handle data sparsity efficiently.
- Compute Item-Item Similarity: For every pair of items, calculate their similarity using your chosen metric (e.g., cosine similarity). This results in an item-similarity matrix.
Example (conceptual Python snippet):
from sklearn.metrics.pairwise import cosine_similarity item_similarity_matrix = cosine_similarity(item_user_matrix.T) Transpose for item-item similarity - Generate Recommendations: For a target user, identify all items they have interacted with. For each of these interacted items, find its most similar items (neighbors) from the item-similarity matrix. Aggregate these similar items, weighting them by similarity and the user's interaction strength (if explicit ratings are available). Exclude items the user has already interacted with.
- Rank and Present: Rank the potential recommendations by their predicted relevance score and present the top N items.
Advanced Note: While neighborhood-based methods (user-based or item-based) are intuitive, more advanced techniques like matrix factorization (e.g., Singular Value Decomposition - SVD, Alternating Least Squares - ALS) can offer better performance and scalability by decomposing the user-item matrix into lower-dimensional latent factor matrices. These methods can often handle data sparsity more effectively.
Phase 3: Addressing Key Challenges and Optimizations
Implementing a recommendation system isn't without its hurdles. Proactive strategies for common problems are essential.
The Cold Start Problem
This occurs when there's insufficient data for new users or new items. Without historical interactions, the collaborative filtering model cannot make accurate recommendations. Solutions include:
- For New Users:
- Ask for initial preferences upon signup.
- Recommend popular or trending items.
- Use demographic information (if available and ethically sourced) to find similar users.
- Implement a temporary content-based filtering approach until sufficient interaction data is collected.
- For New Items:
- Recommend based on popularity or editorial curation.
- Link new items to existing, similar items using item metadata (a hybrid approach).
- Showcase them to a diverse set of users to gather initial interactions.
Data Sparsity
Most user-item matrices are very sparse, meaning only a tiny fraction of possible interactions are recorded. This can lead to inaccurate similarity calculations. Beyond using sparse matrix formats, consider:
- Dimensionality Reduction: Techniques like SVD or Non-negative Matrix Factorization (NMF) can reduce the complexity of the data while preserving essential information, mitigating the effects of sparsity.
- Implicit Feedback Conversion: If you only have implicit data (e.g., purchases), you might infer a "preference score" based on frequency or recency of interaction.
Scalability Challenges
As your user base and item catalog grow, computing similarities and generating recommendations can become computationally expensive. Strategies include:
- Offline Pre-computation: Compute the item-similarity matrix offline and store it. This makes real-time recommendation generation much faster.
- Approximate Nearest Neighbors (ANN): For extremely large datasets, exact nearest neighbor search is too slow. ANN algorithms (e.g., Locality Sensitive Hashing - LSH, Annoy, FAISS) provide fast, approximate similarity searches.
- Distributed Computing: Utilize frameworks like Apache Spark for processing massive datasets and parallelizing computations.
- Regular Updates: The item-similarity matrix doesn't need to be recomputed constantly. Update it periodically (e.g., daily, weekly) based on the rate of new interactions.
Expert Insight: Optimizing for scalability often involves a trade-off between recommendation freshness and computational cost. Understand your system's requirements.
Phase 4: Evaluation, Deployment, and Continuous Improvement
A recommendation system is a living entity that requires constant monitoring and refinement.
Evaluating Your Recommendation System
Rigorous evaluation is crucial to ensure your system is performing as expected and delivering value. Key evaluation metrics include:
- Offline Metrics:
- RMSE (Root Mean Squared Error) / MAE (Mean Absolute Error): For explicit rating prediction, these measure the accuracy of predicted ratings compared to actual ratings.
- Precision and Recall @ N: For top-N recommendations, these measure the proportion of relevant items among the recommended ones (precision) and the proportion of relevant items found (recall).
- F1-Score: The harmonic mean of precision and recall.
- Coverage: The percentage of items that can be recommended.
- Novelty: How often the system recommends items that users haven't encountered before.
- Online Metrics (A/B Testing): This is the ultimate test. Deploy different versions of your recommendation algorithm to distinct user groups and measure real-world impact on key business metrics:
- Click-through rate (CTR)
- Conversion rate (purchases, subscriptions)
- User engagement (time spent, number of sessions)
- Average revenue per user (ARPU)
- User retention
Actionable Tip: Always prioritize online A/B testing results over offline metrics. Offline metrics are useful for quick iteration, but user behavior is the true arbiter of success.
Deployment and Monitoring
Once your model is trained and evaluated, it needs to be integrated into your live system. This typically involves:
- API Endpoint: Expose your recommendation logic via a REST API that your application can call.
- Real-time Inference: Ensure your system can generate recommendations quickly enough for user interaction.
- Monitoring: Continuously monitor system performance, latency, and the quality of recommendations. Look for drift in user behavior or data quality issues. Set up alerts for anomalies.
- Retraining Pipeline: Establish an automated pipeline to periodically retrain your model with fresh data to ensure recommendations remain relevant.
By following these steps, you can build a powerful and effective personalized recommendations system using collaborative filtering that continuously adapts and delights your users.
Frequently Asked Questions
What is the difference between collaborative filtering and content-based filtering?
Collaborative filtering makes recommendations based on user-item interactions, finding patterns in collective behavior ("users who liked this also liked that"). It doesn't need to understand the content of the items themselves. In contrast, content-based filtering recommends items similar to those a user has liked in the past, based on item attributes (e.g., recommending sci-fi movies because a user liked other sci-fi movies). Often, a hybrid recommendation system combines both approaches to leverage their respective strengths and mitigate weaknesses like the cold start problem.
How does collaborative filtering handle new users or new items (the cold start problem)?
The cold start problem is a significant challenge for collaborative filtering because it relies on historical interaction data. For new users, there's no interaction history to find similar users or items. For new items, no one has interacted with them yet. Common strategies involve falling back to non-personalized recommendations (e.g., trending items), using demographic data, or incorporating a temporary content-based filtering approach until sufficient interaction data is gathered. Advanced solutions might involve active learning or leveraging social network data.
What Python libraries are best for implementing collaborative filtering?
For implementing collaborative filtering in Python, several excellent libraries are available. The Scikit-learn library provides tools for similarity calculations (e.g., `cosine_similarity`) and basic matrix operations. For more specialized recommendation system development, the Surprise library is highly recommended; it offers a wide range of predefined collaborative filtering algorithms (like SVD, KNN-based algorithms) and robust evaluation tools. For handling large-scale sparse matrices efficiently, SciPy's sparse matrix module is indispensable. Additionally, tools like Apache Spark MLlib are excellent for distributed computing on massive datasets.
0 Komentar